

Real-Time AI Processing Why Latency is Key for HiSilicon
For HiSilicon AI SoCs, low latency is the most critical performance metric. This hardware focus on low latency performance e

For HiSilicon AI SoCs, low latency is the most critical performance metric. This hardware focus on low latency performance enables real-time data processing. The AI market's growth to a projected $143 billion by 2034 highlights demand for this hardware performance. In systems where latency matters, a delay over 100 milliseconds degrades safety performance. HiSilicon’s specialized hardware architecture prioritizes this end-to-end latency performance. This hardware design ensures superior real-world AI performance. Raw TOPS fails to reflect true hardware performance. This hardware focus on latency performance is key for AI hardware performance, as the hardware itself is the core of AI hardware performance.
Key Takeaways
- Low latency is very important for HiSilicon's AI chips. It means the chip makes decisions quickly, which is key for real-time tasks.
- HiSilicon's special design, called the Da Vinci NPU, helps AI models work fast. It uses a unique 3D Cube to do math quickly.
- Special parts in the chip, like the Image Signal Processor, help the main AI part. They make the whole system faster by doing specific jobs.
- Fast AI processing helps self-driving cars, smart cities, and smart devices. It makes them safer and work better in real life.
WHY LATENCY MATTERS IN EDGE AI

In edge AI applications, every millisecond counts. The system must process data streams in real time, where falling behind can lead to missed events or incorrect actions. This is why latency matters. Control algorithms depend on immediate inference decisions to maintain stability and safety. A delay can compromise the entire system's performance. True hardware performance is not just about processing power; it is about the speed of the final, actionable output.
DEFINING AI PROCESSING LATENCY
Professionals formally define AI inference latency as the time an AI model takes to receive an input and return a prediction. This measurement is typically expressed in milliseconds (ms). However, end-to-end latency provides a more complete picture of system performance. It covers the entire journey from data capture to the final action.
This total latency includes several distinct stages:
- Data Ingestion and Pre-processing: The hardware first prepares input data. This step involves formatting and validating the data before it reaches the AI models.
- Model Inference: This is the core computation time. The hardware runs the AI models to generate a prediction based on the input data. The inference performance here is critical.
- Post-processing and Output: The hardware formats the model's output. It prepares the result for the next system component, such as a robotic arm controller or a display.
Note: For interactive AI, other metrics also highlight hardware performance. Time to First Token (TTFT) measures how quickly a user gets the first piece of a response, which is vital for a smooth user experience.
LIMITATIONS OF GENERAL-PURPOSE CPUS
General-purpose CPUs are not built for the demands of modern AI. CPUs use a small number of powerful cores, usually between 4 and 64. This architecture excels at complex, sequential tasks. However, AI models require massively parallel computations, running thousands of simple operations at once. This mismatch creates a significant performance bottleneck. The CPU's design limits its inference performance for parallel workloads.
Even in systems with a powerful GPU, the CPU can constrain overall performance, especially in latency-sensitive applications. The CPU struggles to feed data to the accelerator quickly enough, which hurts the system's inference performance. This is why specialized hardware is necessary for optimal AI performance.
Benchmarks clearly show the performance gap between CPUs and specialized hardware like Neural Processing Units (NPUs). For common AI models like YOLOv3, NPUs deliver far better inference performance.
| System Type | Relative Latency Reduction |
|---|---|
| CPU-Only System | Baseline |
| NPU-Powered System | ~1.6x Faster |
This data shows that dedicated hardware significantly reduces the time needed to run AI models. The architectural advantage of NPUs directly translates to lower latency and superior inference performance. The chart below further illustrates how different specialized hardware platforms achieve varying latency for popular AI models.
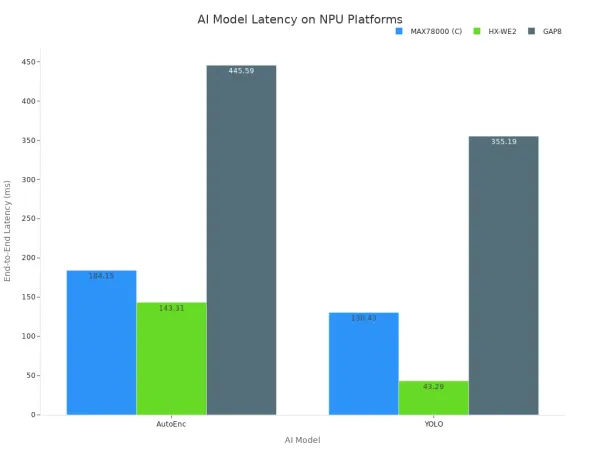
Ultimately, relying on CPUs for real-time AI tasks compromises system responsiveness. The hardware is simply not designed for the job. Achieving the low latency that matters requires hardware purpose-built for AI models, ensuring top-tier inference performance and reliability.
HISILICON'S ARCHITECTURE FOR LOW LATENCY

HiSilicon achieves its industry-leading low latency performance through a holistic hardware architecture. This design goes beyond a single powerful processor. It integrates specialized compute cores, a high-speed memory system, and dedicated hardware accelerators. This combination ensures that data moves and gets processed with maximum efficiency, which is essential for real-time AI applications. The overall system performance depends on this tight integration.
THE DA VINCI NPU CORE
The Da Vinci Neural Processing Unit (NPU) is the heart of HiSilicon's AI hardware. This NPU is a powerful AI accelerator designed specifically for the mathematical operations that power modern AI models. Its architecture is not uniform; it combines different types of compute units to optimize performance. This heterogeneous design is a key reason for its excellent inference performance.
The core contains three main components working together:
- Scalar Units: These handle general logic and control flow for the AI models.
- Vector Units: These are excellent at running many simple operations at once, a common need for certain layers in AI models.
- 3D Cube Units: This is the most critical component for AI acceleration. These units are built to perform matrix multiplication at incredible speeds.
This structure allows the Da Vinci core to process complex AI models with minimal delay. The cube units handle the heavy lifting of matrix math, while the vector and scalar units manage the surrounding tasks. This division of labor inside the AI accelerator ensures that no single part of the hardware creates a bottleneck. The result is superior inference performance and lower latency for demanding AI workloads. These AI accelerators are fundamental to the system's overall performance.
ON-CHIP MEMORY AND INTERCONNECTS
A fast NPU needs fast data. If the AI accelerator must wait for data, its performance advantage is lost. HiSilicon's hardware design addresses this challenge with a sophisticated on-chip memory hierarchy and high-speed interconnects. These components create a data superhighway, minimizing the latency associated with moving information around the chip. This efficient data flow is critical for the hardware's inference performance.
HiSilicon SoCs use advanced interconnects to link the NPU, CPU, and memory. This ensures all components can communicate with minimal delay. The choice of memory technology also plays a vital role in system performance.
| Chip Model | Interconnect | Memory Technology |
|---|---|---|
| Kirin 960 | ARM CCI-550 | LPDDR4-1600 (64-bit dual-channel) |
| Kirin 970 | ARM CCI-550 | LPDDR4 |
Beyond the main memory, the system uses several layers of on-chip memory (caches). The Da Vinci NPU itself contains its own local memory. This allows the AI accelerator to keep frequently used data for AI models right next to the compute units, drastically reducing data access latency. This architecture also improves power efficiency. Efficient on-chip data flow, often managed by a Network-on-Chip (NoC), reduces power consumption by sending data in flexible packets. This approach lowers the physical wire count and improves performance. Other techniques further enhance this efficiency:
- Fine-grained Gating: This method uses clock gating to regulate data flow between hardware units.
- Buffering: Explicit buffers (FIFOs) ensure data is available precisely when the AI accelerator needs it, preventing stalls and wasted energy.
DEDICATED HARDWARE ACCELERATION
The NPU is the star player, but it is not the only hardware accelerator on the team. HiSilicon SoCs integrate a suite of dedicated hardware accelerators that handle specific tasks. These accelerators offload work from the CPU and NPU, reducing the end-to-end latency of the entire AI pipeline. This approach is vital for complex tasks like real-time video analysis and enables effective on-device inference.
In computer vision applications, the Image Signal Processor (ISP) is a crucial hardware accelerator. The ISP works directly with the NPU to deliver better inference performance.
- The ISP handles initial image processing tasks like High Dynamic Range (HDR) fusion and advanced noise reduction.
- It prepares and optimizes the video data specifically for the AI models running on the NPU.
- This pre-processing by a dedicated hardware accelerator means the NPU receives clean, ready-to-analyze data, which speeds up the final AI result.
Similarly, hardware-based video encoders and decoders are essential AI accelerators for analyzing high-resolution video streams. These accelerators manage the entire video processing pipeline on a single chip.
- They decode incoming video streams without burdening the CPU.
- They allow the NPU to analyze the video locally.
- They transmit only critical event data, which drastically reduces network bandwidth and storage costs.
This team of specialized hardware accelerators ensures that every stage of an AI task, from data capture to final output, is optimized for speed. This comprehensive approach to hardware design is what gives HiSilicon its edge in low-latency performance for real-time AI. The synergy between these accelerators delivers a level of performance that a single processor cannot match.
REAL-WORLD LOW-LATENCY APPLICATIONS
Low-latency hardware unlocks a new generation of intelligent systems. The performance of these systems depends on immediate data processing. HiSilicon's hardware architecture provides the speed needed for critical real-world AI applications. The superior performance of its AI models enables instant decision-making where milliseconds matter.
AUTONOMOUS SYSTEMS
In autonomous systems, low latency is a non-negotiable requirement for safety and precision. The hardware must process sensor data and execute AI models with minimal delay to ensure reliable performance.
- Autonomous Vehicles: For a self-driving car, detecting a pedestrian and applying the brakes requires an end-to-end latency of 50 to 100 milliseconds. Any delay beyond this compromises safety. The vehicle's hardware must deliver this performance consistently.
- Industrial Robotics: On an assembly line, robots need rapid feedback to perform precise tasks. Sub-100ms execution cycles for AI models allow for better quality control and enhanced worker safety. This low-latency hardware performance directly improves manufacturing throughput.
SMART INFRASTRUCTURE
Smart cities and factories use on-camera AI analysis to improve efficiency and security. This requires powerful edge hardware capable of processing video streams in real time. The performance of these AI models is key to their success.
Real-Time Threat Detection: In smart cities, AI cameras monitor public spaces. The hardware analyzes video feeds to identify traffic violations, abandoned objects, or other potential threats, enabling an immediate response. This AI performance helps law enforcement and optimizes emergency services.
In smart factories, AI vision systems provide instant quality control. The hardware runs inspection models that analyze products on the assembly line, identifying defects like scratches or misalignments. This immediate feedback improves product quality without slowing down production. The AI models' performance is critical here.
SMART DEVICES AND MEDIA
Low-latency AI processing enhances the user experience in consumer electronics and healthcare devices. The hardware enables sophisticated features that run directly on the device.
Smart TVs use AI models for real-time 8K video upscaling. The hardware's AI processor analyzes content frame-by-frame to enhance details and reduce noise, delivering a superior picture. This high-level performance happens instantly. For telemedicine and wearables, on-device hardware analyzes biometric data. Emergency event detection models require a latency of less than 50 ms to alert users or medical personnel. This rapid AI performance can be life-saving.
For real-time edge AI, end-to-end latency matters. Raw computational throughput alone does not define true hardware performance. HiSilicon's hardware architecture, with its Da Vinci NPU and dedicated hardware accelerators, delivers this critical low-latency performance. The performance of these hardware accelerators is key. The hardware accelerators provide excellent performance.
Note for Developers: You must benchmark hardware for latency. This guarantees real-world hardware performance and reliability. Latency matters for this hardware performance. The hardware accelerators and hardware deliver this performance. The hardware accelerators' performance is vital. The hardware performance depends on these hardware accelerators.
FAQ
Why is latency more important than TOPS for edge AI?
TOPS measures raw processing power. Latency measures the total time for a decision. For real-time applications like autonomous driving, a fast decision is more critical for safety and performance than just high computational throughput.
A low latency ensures the system can react instantly to new information.
What is the Da Vinci NPU?
The Da Vinci NPU is HiSilicon's specialized AI accelerator. It uses a unique 3D Cube architecture for matrix math. This design significantly speeds up AI model computations. It directly reduces inference latency and improves overall system performance for real-time tasks.
How do hardware accelerators improve AI performance?
Hardware accelerators, like an Image Signal Processor (ISP), handle specific jobs. They offload tasks from the main processor. This parallel processing reduces bottlenecks. The entire AI pipeline runs faster, lowering end-to-end latency and enabling efficient on-device inference.
What applications require ultra-low latency?
Applications needing immediate action require low latency. These systems depend on rapid, real-time decision-making. Key examples include:
- Autonomous systems (vehicles, robotics) 🤖
- Smart infrastructure (threat detection) 🏙️
- Advanced media (8K upscaling) 📺
- Telemedicine (emergency alerts) ❤️🩹




